
 Speaker: Simone Rebora @srebora, Marina Lehmann @Marina_Le, Anne Heumann
Speaker: Simone Rebora @srebora, Marina Lehmann @Marina_Le, Anne Heumann
 Affiliation: Johannes Gutenberg University of Mainz
Affiliation: Johannes Gutenberg University of Mainz
Title: *Sentiment Analysis of German children’s and young adult fiction. Can dictionary-based approaches keep up with Transformer-based models? *
Abstract (long version below): In this paper, we present two studies comparing a dictionary-based approach (“SentiArt”) with Transformer models for Sentiment Analysis in German. As ground truth data we use reader response ratings from the 4books dataset. In the first study SentiArt is adapted to the dataset and Transformer models are fine-tuned before comparing their performance. Here, Transformers clearly outperform SentiArt. In the second study the performance of SentiArt without adaptation is compared to pretrained Transformers from different domains (without fine-tuning). In this case, SentiArt performs better than pretrained Transformers. We conclude that SentiArt continues to be a valuable alternative when the resources for fine-tuning (e.g. human raters, high computing power) are not available.

")
 Long abstract
Long abstract
This paper presents a comparison between two main approaches in Sentiment Analysis: dictionary-based approaches (Fehle et al. 2021) and Transformer-based approaches (for previous performance comparisons, see: Rebora et al. 2022). We used SentiArt (Jacobs 2019) as a dictionary-based approach and we took as reference point the 4books dataset (Lüdtke and Jacobs 2023), an extensive collection of reader responses to four children’s and young adult novels in German. Such a comparison is the necessary groundwork for the development of a research that aims at predicting reader responses to narratives.
The 4books dataset, developed in the context of the CHYLSA project (“Children’s and Youth Literature Sentiment Analysis”), hosts a wide variety of reader response ratings (ranging from valence and arousal to suspense and transportation) for two children’s novels (Mebs 2005; Ende 2020) and two young adult novels (Green 2012; Rowling 2018). For our studies, we took as ground truth the mean of the valence ratings (scale: -3 to +3) added in parallel by 20 readers (all German mother tongue, mean age = 22.9, sd = 5.04) on the 22,860 sentences of the four books.
Transformer models have been applied widely in Sentiment Analysis in recent years and are considered as a promising approach (Schmidt 2022). However, they also require a considerable amount of computing power and large training corpora to unfold their full potential. Therefore, for many research scenarios in which those requirements are not available, dictionary-based approaches are still the method of choice. SentiArt is a special kind of dictionary-based Sentiment Analysis tool, as it can be tailored to different contexts via vector space representations of language (Joulin et al. 2017). If an extensive corpus of texts from a certain language, period, or genre is available, SentiArt’s sentiment dictionary can be modified automatically by calculating distances between all words in the corpus and a predefined set of seed words (expressing basic emotions, positive/negative valence, etc.). Transformer models are similarly based on vector representations of language, but they are more complex, implying for example the usage of context-dependent vector representations, deep neural networks with self-attention mechanisms (to identify which parts of a sentence are more important for determining its meaning), and bidirectional processing of text (including context information from both directions to allow a better recognition of its syntactic structure). However, these advantages come at the cost of high computing power since Transformer models need graphics processing units (GPUs) to be fine-tuned.
We performed our comparison through two studies. In the first one, we adapted SentiArt and fine-tuned the Transformer models to the 4books dataset. We predicted the valence on a sentence level by using ratings of 20 readers as point of reference. For Transformers, the basic German language model “gbert-base” (Chen et al. 2020) was fine-tuned using the human ratings for linear regression. For adapting SentiArt, first we applied univariate linear regression using as a predictor the Affective-Aesthetic Potential scores, produced for each sentence by calculating the mean of the scores assigned by the sentiment dictionary to content words. Second, we applied multivariate linear regression, random forest, and feedforward neural networks with 21 predictors (such as Ekman’s six basic emotions, abstractness/concreteness, and many others). Figure 1 shows the results obtained by calculating R2 in a 10-fold cross validation procedure repeated for each book. Overall, the most basic Transformer model clearly outperforms all attempted approaches with SentiArt.
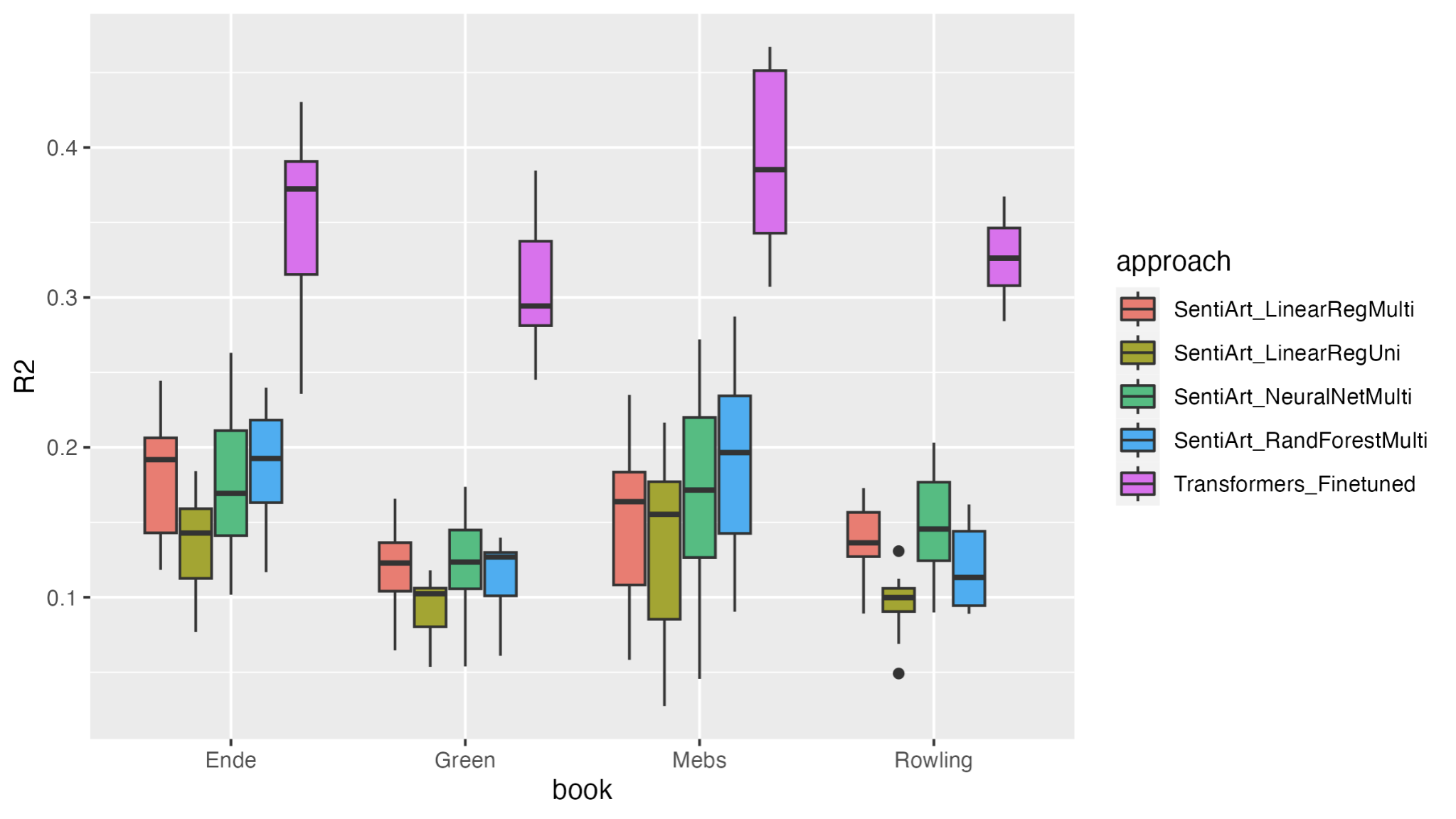
Figure 1. Results of first study.
In the second study, we decided to also test pretrained Transformer models and SentiArt without adaptation. We did this in order to emulate a typical situation in research, where resources for extensive rating campaigns (like the one for the 4books dataset) might not be available and researchers are frequently obliged to rely just on the available tools and datasets. For Transformers, we searched the Hugging Face repository for any pretrained model tagged for German that contained the “sentiment” keyword (on March 3, 2023, the search produced seven results, six of which were usable via the transformers Python package, cf. Wolf et al. 2020). When applied to text, the models produced a set of probabilities related to three to five different classes (“positive”, “neutral”, and “negative” in different nuances). To convert these probabilities into a single score for each sentence, we first converted classes to numbers (e.g. “positive”: +1; “neutral”: 0; “negative”: -1), we then multiplied each number by the probability of the corresponding class and finally summed the obtained values (a procedure that can be synthetically described as a “weighted mean”). For SentiArt, we simply used the mean Affective-Aesthetic Potential scores per sentence (see above, univariate approach from study 1). Table 1 shows Pearson correlation coefficients for the predicted and actual values: with just one marginal exception, SentiArt always outperforms pretrained Transformer models.
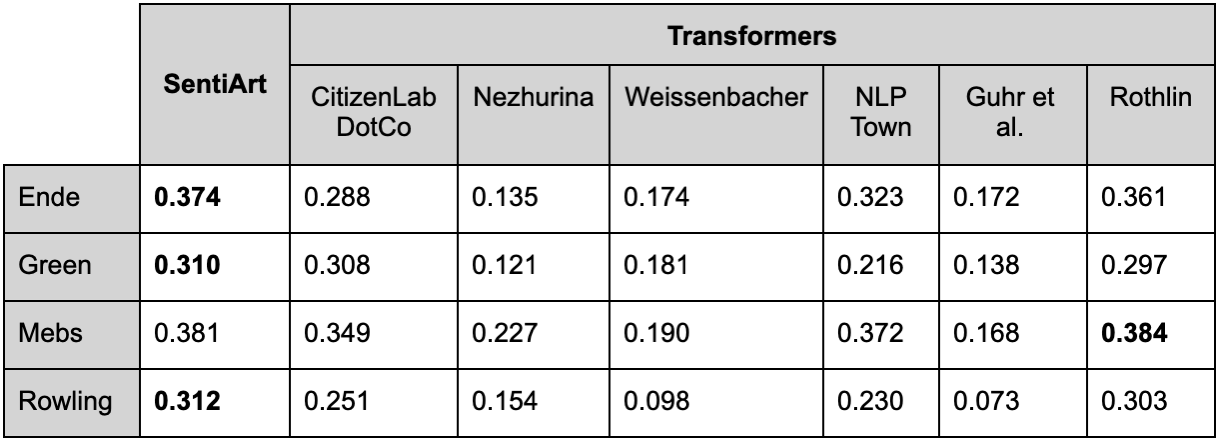
Table 1. Results of second study.
It should also be noted how Sentiment Analysis in literary studies generally focuses on large-scale phenomena like emotional arcs and plot structures, which do not require high efficiency at the level of the sentence. The weak correlation scores shown in Table 1 increase in fact substantially (>0.69 for SentiArt) when applying a 10% moving average to the sentence scores, as done by Jockers (2014) to generate his “plot arcs”.
Our research has shown how, notwithstanding the undeniable potential of fine-tuned Transformer models, SentiArt remains a valuable option whenever computing power and training data for fine-tuning Transformer models are not available. Compared to pretrained Transformer models, SentiArt has also the advantage of a higher explainability (contrary to the “opaqueness” of deep neural networks), it is faster, and it requires less computational power (being in a sense more environmentally friendly). Unavoidably, the results presented in this paper depend on the characteristics of the dataset (results might differ for different languages and genres), but they suggest how, for computational research on reader responses to literary texts, fine-tuned Transformer models provide the best performance, but dictionary-based Sentiment Analysis methods like SentiArt can and should still be adopted if resources are limited. Therefore, future research could focus not only on optimising the fine-tuning process for Transformer models, but also on improving dictionary-based approaches (like considering emotion shifters such as negations/intensifiers, or giving different weights to different parts of speech).
References
Chan, Branden, Stefan Schweter, and Timo Möller. “gbert-base.” Hugging Face. Accessed March 3, 2023. deepset/gbert-base · Hugging Face.
CitizenLabDotCo. “twitter-xlm-roberta-base-sentiment-finetunned.” Hugging Face. Accessed March 3, 2023. https://huggingface.co/citizenlab/twitter-xlm-roberta-base-sentiment- finetunned.
Ende, Michael. 2020. Jim Knopf und Lukas der Lokomotivführer . 19th edition. Stuttgart: Thienemann.
Fehle, Jakob, Schmidt, Thomas, and Christian Wolff. 2021. Lexicon-based Sentiment Analysis in German. Systematic Evaluation of Resources and Preprocessing Techniques, In Proceedings of the 17th Conference on Natural Language Processing (KONVENS 2021) , 86–103, Düsseldorf, Germany. KONVENS 2021 Organizers.
Green, John. 2012. Das Schicksal ist ein mieser Verräter . Translated by Sophie Zeitz. 4th edition. München: Hanser.
Guhr, Oliver, Anne-Kathrin Schumann, Frank Bahrmann, and Hans Joachim Böhme. “german-sentiment-bert.” Hugging Face. Accessed March 3, 2023. oliverguhr/german-sentiment-bert · Hugging Face.
Jacobs, Arthur M. 2019. “Sentiment Analysis for Words and Fiction Characters From the Perspective of Computational (Neuro-)Poetics.” Frontiers in Robotics and AI 6 (July). https://doi.org/10.3389/frobt.2019.00053.
Jockers, Matthew. 2014. “A Novel Method for Detecting Plot.” 2014. http://www.matthewjockers.net/2014/06/05/a-novel-method-for-detecting-plot/.
Joulin, Armand, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. 2017. “Bag of Tricks for Efficient Text Classification.” In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers , 427–31. Association for Computational Linguistics.
Lüdtke, Jana, and Arthur M. Jacobs. 2023. “On a rollercoaster with Frieder, Jim, Hazel and Harry: Identifying emotional arcs in reader responses to children and youth books”, IGEL 2023 Conference Abstract.
Mebs, Gudrun. 2005. “Oma!”, schreit der Frieder . 20. Auflage. Aarau, Frankfurt am Main: Sauerländer.
Nezhurina, Marianna. “bert-multilingual-sentiment.” Hugging Face. Accessed March 3, 2023. marianna13/bert-multilingual-sentiment at main.
NLP Town. “bert-base-multilingual-uncased-sentiment.” Hugging Face. Accessed March 3, 2023. nlptown/bert-base-multilingual-uncased-sentiment · Hugging Face.
Rebora, Simone, Thomas C. Messerli, and J. Berenike Herrmann. 2022. “Towards a Computational Study of German Book Reviews. A Comparison between Emotion Dictionaries and Transfer Learning in Sentiment Analysis.” In DHd2022: Kulturen Des Digitalen Gedächtnisses . Konferenzabstracts, 354–56.
Rothlin, Tobias. “bert-base-german-cased_German_Hotel_sentiment.” Hugging Face. Accessed March 3, 2023. https://huggingface.co/Tobias/bert-base-german- cased_German_Hotel_sentiment.
Rowling, J. K. 2018. Harry Potter und der Halbblutprinz . Translated by Klaus Fritz. Harry Potter 6. Hamburg: Carlsen.
Schmidt, Thomas , Jakob Fehle, Maximilian Weissenbacher, Jonathan Richter, Philipp Gottschalk, and Christian Wolff. 2022. “Sentiment Analysis on Twitter for the Major German Parties during the 2021 German Federal Election.” In Proceedings of the 18th Conference on Natural Language Processing (KONVENS 2022) , 74–87, Potsdam, Germany. KONVENS 2022 Organizers.
Weissenbacher, Max. “gBERt_base_twitter_sentiment_politicians.” Hugging Face. Accessed March 3, 2023. mox/gBERt_base_twitter_sentiment_politicians · Hugging Face.
Wolf, Thomas, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, et al. 2020. “Transformers: State-of-the-Art Natural Language Processing.” In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , 38–45. Online: Association for Computational Linguistics. Transformers: State-of-the-Art Natural Language Processing - ACL Anthology.