
 Speaker: Jana Lüdtke @jluedtke
Speaker: Jana Lüdtke @jluedtke
 Affiliation: Freie Universität Berlin
Affiliation: Freie Universität Berlin
Title: On a rollercoaster with Frieder, Jim, Hazel and Harry: Identifying emotional arcs in reader responses to children and youth books
Abstract (long version below): In the ‘4books-study’, 20 adults entirely read one of four children and youth books, evaluating the emotional impact of each sentence on valence and arousal. Additional ratings were collected after each chapter and the end of the book. Analysis of sentence valence ratings indicated a higher emotion potential for children’s books - mainly due to a significantly higher proportion of positively rated sentences. Emotional arcs were computed for books and chapters. A hierarchical time series clustering at chapter level identified six prototypical curves only partially fitting with basic patterns suggested by Reagan et al. (2016) or Archer and Jockers (2016).

")
 Long abstract
Long abstract
In recent years, especially within computational approaches, many researchers have focused on the emotional side of narrative plots - the textually encoded emotional content that might evoke emotional experience in readers (e.g., Hogan 2011). For example, Reagan et al. (2016) analyzed more than 1000 books in search of prototypical trajectories. They calculated average sentiment scores for text segments using a text-based sentiment analysis measuring joy. They claimed to have found empirical support for the six basic shapes of so-called emotional arcs proposed by Vonnegut. Using text-based valence values Archer and Jockers (2016) described seven different fundamental plots. Despite the growing number of studies that use different sentiment tools to analyze the emotional trajectories in literary texts (Elkins, 2022; Jacobs, 2019; Kim & Klinger, 2019), there is a lack of empirical studies focusing on the responses of real readers. The presented 4books-study addresses precisely this gap. Based on reader’s responses on sentence, chapter and book level, we address the question if prototypical shapes could be identified in the evoked emotional experience in readers.
Sample and procedure
In an online study, we presented four popular children’s and youth books (see Table 2 for an overview) to a total 80 native German participants (meanage = 23.33, SDage = 6.4; 64 women, see Table 1). Each participant read one book chapter by chapter. All chapters were presented sentence by sentence via the online platform Sosci survey (Leiner, 2021), so readers could evaluate theemotional impact of each sentence on the dimension’s valence (measured from 1 = ’very negative’ to 7 = ‘very positive’) and arousal (measured from 1 = calming to 5 = exciting), as these two dimensions are often used in studies on emotion. Once all sentences in a chapter had been read and evaluated, participants proceeded to rate valence and arousal of the chapter as a whole. After each chapter they also answered two to four multiple-choice comprehension questions and completed a brief questionnaire about their reading experience. In total, participants needed between two and six weeks to read one book. Each book was read and evaluated by 20 participants.

Table 1: Overview about the children and youth books used in the 4books-study Children’s books
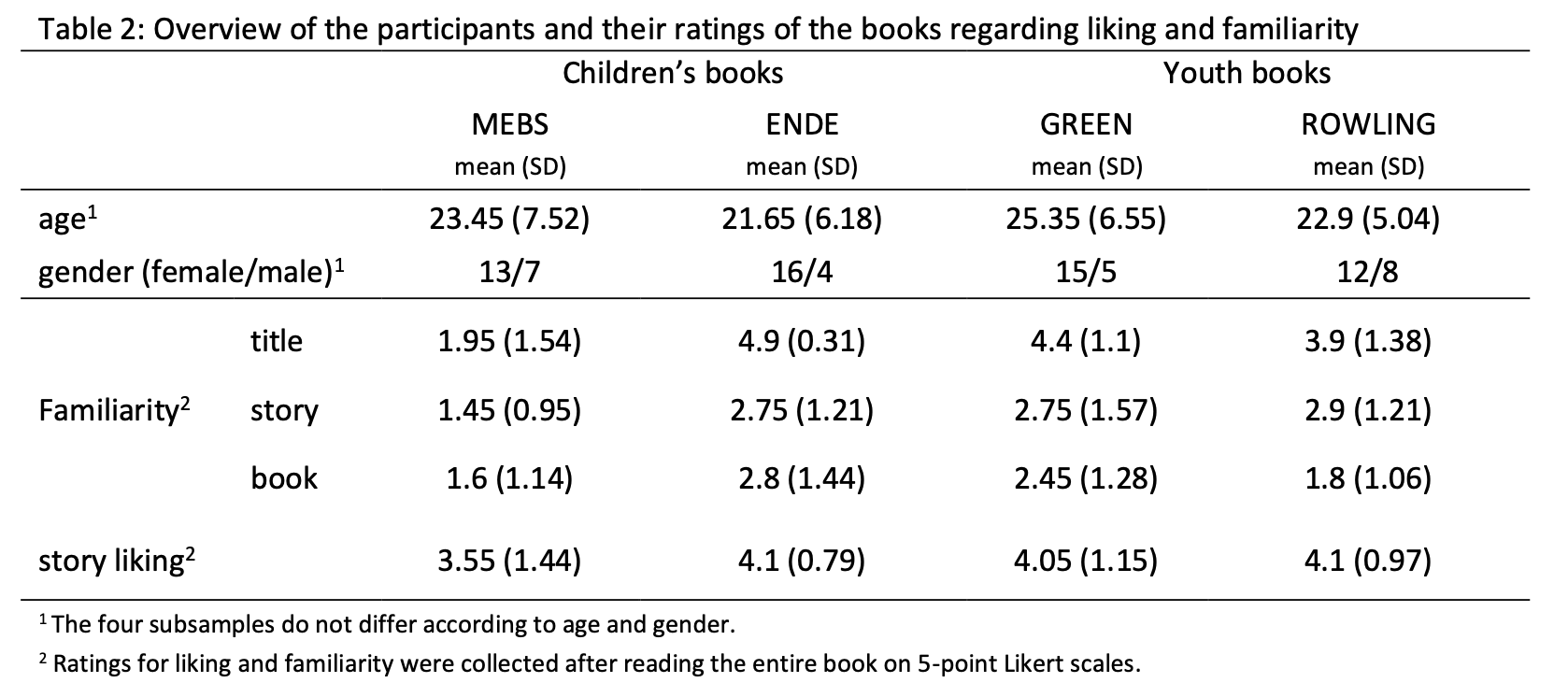
Table 2: Overview of the participants and their ratings of the books regarding liking and familiarity
Data analysis
All analyses reported here were done on the average valence values for each sentence [1] and chapter. Based on the average valence values, all sentences were categorized as negative, neutral, or positive, with a cut-off at 3.5 and 4.5, respectively. Relative frequencies for each sentence type in each chapter were calculated. Emotional arcs for each book and chapter were calculated by applying a discrete cosine transformation (DCT [2]). To account for different chapter and book lengths, we transformed the narrative time indicated by the position of a sentence in a chapter or book to a uniform window reaching from 1 to 100. To identify prototypical arcs at the chapter level, we performed a hierarchical clustering analysis with z standardized values (Paparrizos & Gravano) of the emotional arcs and dynamic time warping as distance measure. Six different cluster evaluation indices were used to identify the best cut-off for the final cluster solution [3].
Results
Figure 1 depicts the relative frequency of negative, neutral, and positive sentences in the chapters of each book. The two children’s books, ‘Frieder’ and ‘Jim’, are dominated by positive sentences, whereas in the two youth books the prevalent sentence category is neutral. Only in ‘Harry’ are the positive sentences scarcest.
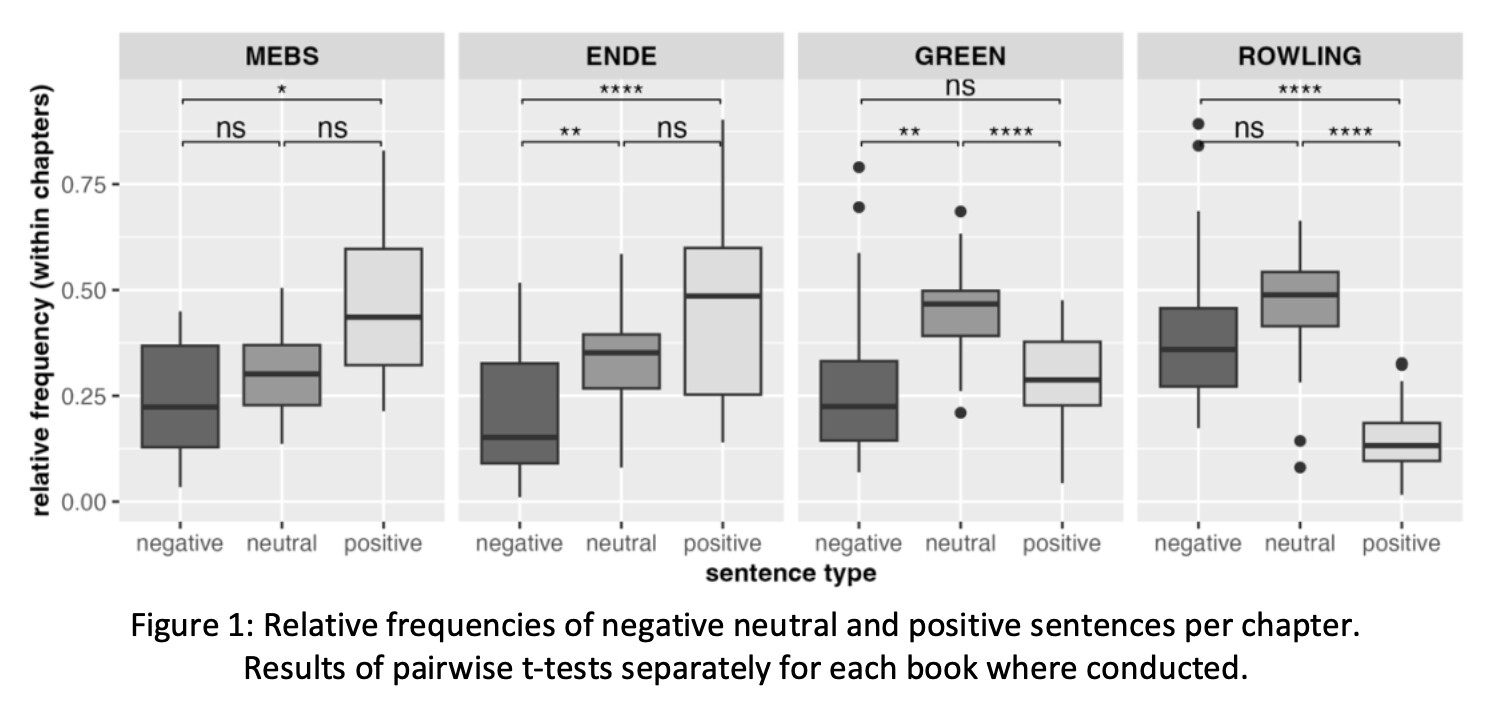
Figure 1: Relative frequencies of negative neutral and positive sentences per chapter. Results of pairwise t-tests separately for each book where conducted.
The emotional arcs for the entire books are depicted in Figure 2. Overall, the positivity bias observed in the children’s books is also visible in the emotional arcs. Both children’s books are characterized by a happy ending, which is the most positive part in the entire narrative. The two youth books tend to become more positive, although the mean values for the final chapters are not higher than the mean values of all other chapters. The comparison of the emotional arcs with the ratings of the chapters as a whole (depicted in red) show high similarities for all books, which speaks for the meaningfulness of the arcs.
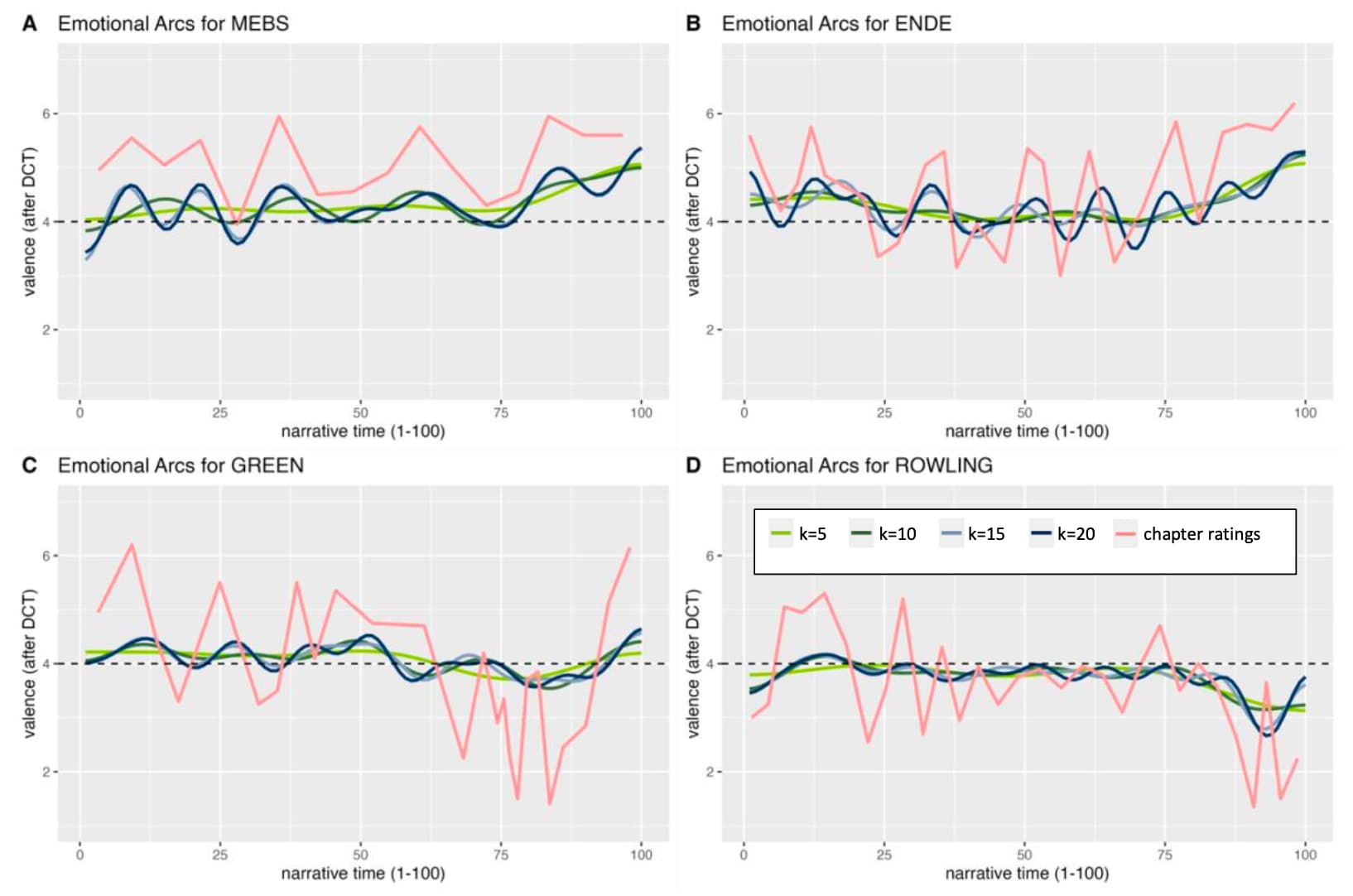
Figure 2: Length normalized emotional arcs for the four books, with different amounts of dimensional reductions depicted by different colors and valence ratings for the entire chapters (red). The positive turn at the end of Rowling’s book Harry Potter (D) becomes visible only when using a less strong smoothing (see C and D)
The final hierarchical clustering of the emotional arcs at chapter level indicated a good solution with six clusters, which is depicted in Figure 3. Table 3 describes the number of chapters from each book that belong to each cluster. Clusters 1, 2, and 3 are characterized by having an outcome that is more positive than the beginning. Participants rated the chapters belonging to these clusters as most positively. Cluster 4 ends as positive as it starts, chapters were evaluated as neutral. Clusters 5 and 6 are characterized by a negative ending, but only the chapters belonging to cluster 6 were evaluated negatively.
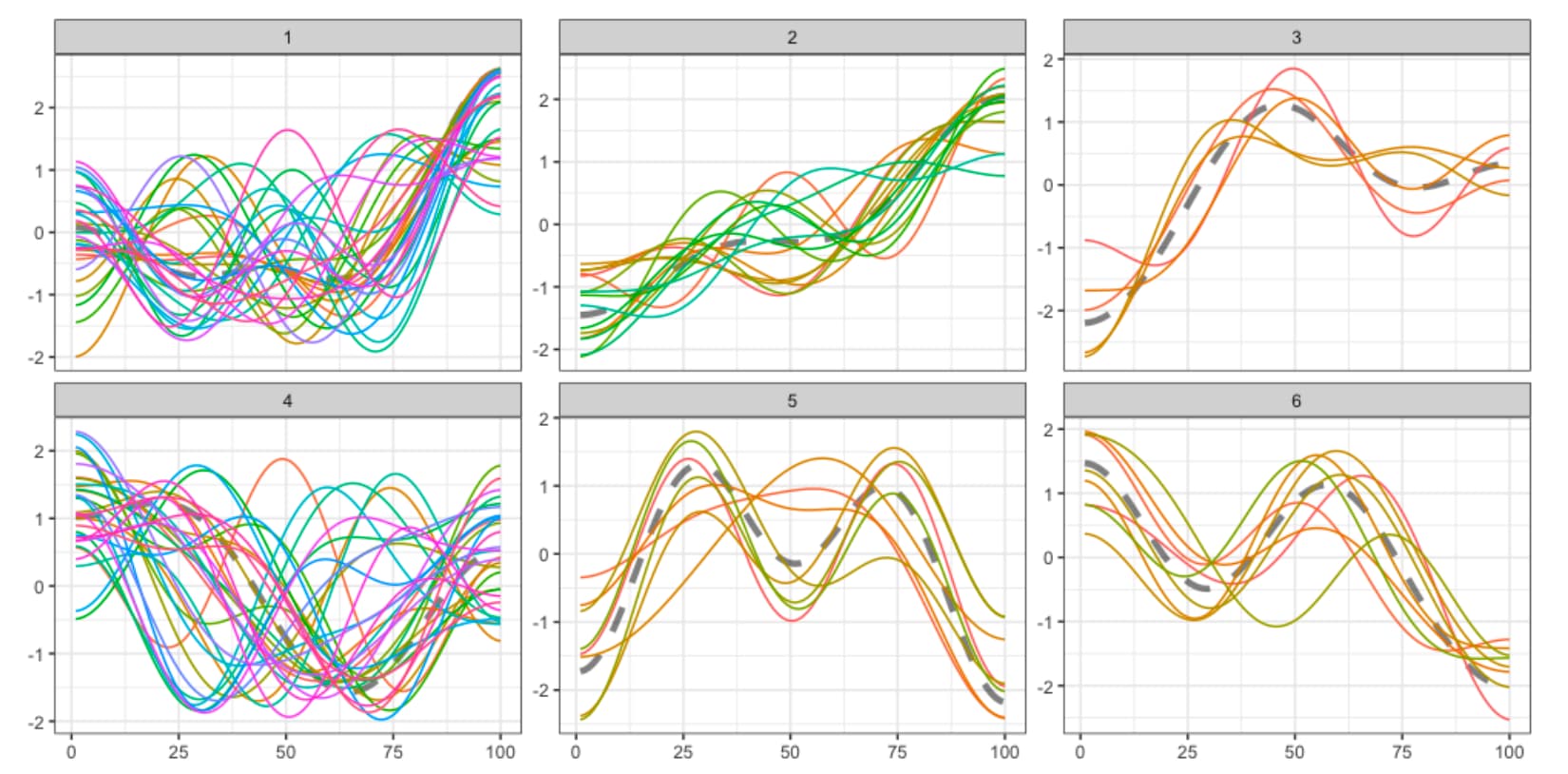
Figure 3: Grouping of the emotional arcs at chapter level in six different clusters. The prototypical shape for each cluster is depicted with a dashed gray line.
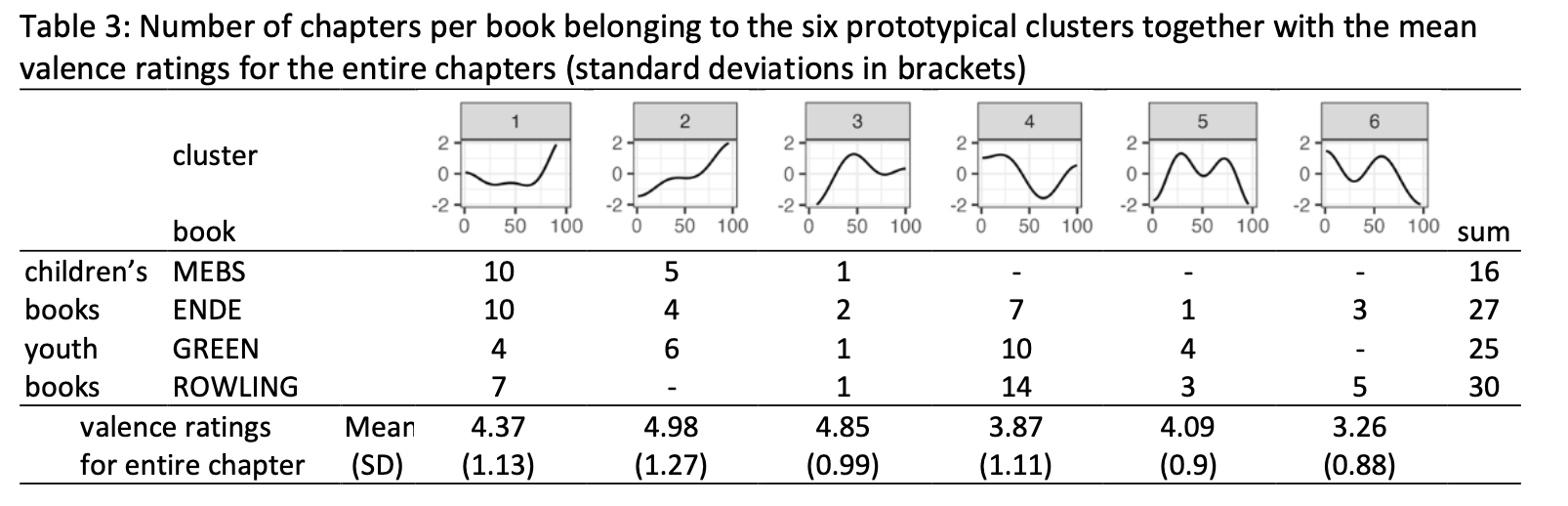
Table 3: Number of chapters per book belonging to the six prototypical clusters together with the mean valence ratings for the entire chapters (standard deviations in brackets)
Discussion
The analysis of the valence ratings demonstrates a strong positivity bias for children’s books and an increase of neutral sentences in youth books. The emotional arcs underlined the positivity bias for children’s books. Emotional arcs with a negative ending could be observed primarily for chapters from youth books. Whether differences between the here identified prototypical trajectories and former ones reflects differences in the levels of granularity (chapter vs. book) or differences between text analysis and induced reader responses needs future research.
References
Archer, J., & Jockers, M. L. (2017). The Bestseller code: Anatomy of the blockbuster novel (reprint edition). GRIFFIN.
Elkins, K. L. (2022). The shapes of stories: Sentiment analysis for narrative. Cambridge University Press.
Ende, M. (2020). Jim Knopf und Lukas der Lokomotivführer. 19th edition. Stuttgart: Thienemann.
Green, J. (2012). Das Schicksal ist ein mieser Verräter. Translated by Sophie Zeitz. 4th edition. München: Hanser. Hogan, Patrick Colm (2011). Affective narratology: The emotional structure of stories. Lincoln/ London: Nebraska Press.
Jacobs, A. M. (2019). Sentiment analysis for words and fiction characters from the perspective of computational (neuro-)poetics. Frontiers in Robotics and AI, 6. https://doi.org/10.3389/frobt.2019.00053
Kim, E., & Klinger, R. (2019). A survey on sentiment and emotion analysis for computational literary studies. Zeitschrift Für Digitale Geisteswissenschaften. A Survey on Sentiment and Emotion Analysis for Computational Literary Studies | ZfdG - Zeitschrift für digitale Geisteswissenschaften
Leiner, D. J. (2021). SoSci Survey (Version 3.2.31) [Computer software]. Available at https://www.soscisurvey.de
Mebs, G. (2005). “Oma!”, schreit der Frieder. 20. Auflage. Aarau, Frankfurt am Main: Sauerländer. Paparrizos, J., & Gravano, L. (2015). k-shape: Efficient and accurate clustering of time series. SIGMOD Rec., 45(1):69–76, June 2016.
Reagan, A. J., Mitchell, L., Kiley, D., Danforth, C. M., & Dodds, P. S. (2016). The emotional arcs of stories are dominated by six basic shapes. EPJ Data Science, 5(1), Article 1. The emotional arcs of stories are dominated by six basic shapes | EPJ Data Science | Full Text
Rebora, S., Lehmann, M. & Heumann, A. (2023). Sentiment Analysis of German children’s and young adult fiction. Can dictionary-based approaches keep up with Transformer-based models?, Abstract. Submitted to IGEL 2023 conference.
Rowling, J. K (2018). Harry Potter und der Halbblutprinz. Translated by Klaus Fritz. Harry Potter 6. Hamburg: Carlsen.
Appendix
Figure 4 depicted the result of the cluster evaluation: Six different cluster evaluation indices (cvi) were calculated for the cluster solutions with 3 to 10 clusters. As visible in Figure 4, the solution with six clusters might be the best when taken into account all different cvi’s.
For six clusters the indices Davies-Bouldin, modified Davies-Bouldin and COP have relative low values, whereas the indices Calinski-Harabasz, Dunn and Silhouette have large values.
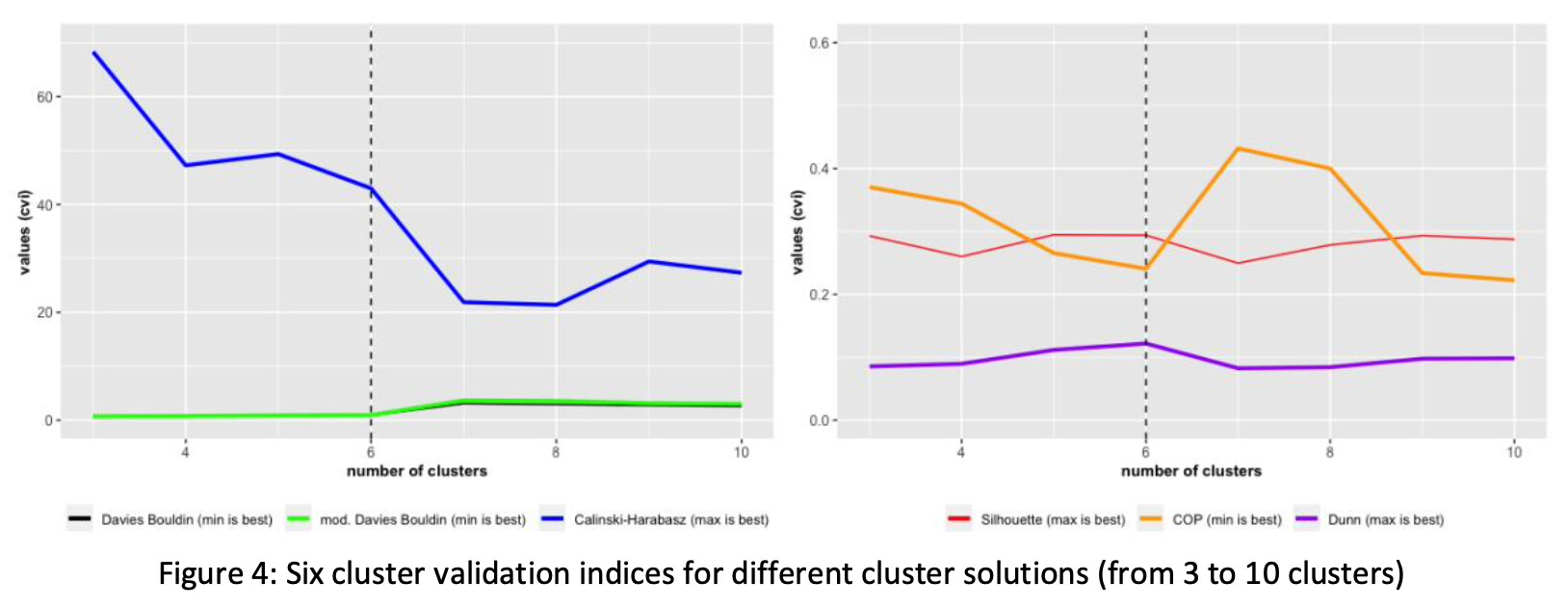
Figure 4: Six cluster validation indices for different cluster solutions (from 3 to 10 clusters)
Foot notes
[1]: Also Rebora, Lehmann and Heumann (2023) used that data for their contribution.
[2]: DCT was applied to reduce the dimensionality of the time series resulted from the valence ratings for each sentence. At book level, we tested different levels of granularity. We reduced the data to 20,15, 10 and 5 dimensions. As there is no gold standard for smoothing time series resulting from sentiment analysis or reader response date (but see Elkins 2022 for a first discussion), we chose 4 dimensions for the smoothing at chapter level because the chapters are shorter.
[3]: The results of the cluster evaluation is depicted in Figure 4 in the appendix.