
 Speaker: Andreas van Cranenburgh @andreasvc
Speaker: Andreas van Cranenburgh @andreasvc
 Affiliation: University of Groningen
Affiliation: University of Groningen
Title: Annotation and Prediction of Emotion Arcs of Movies
Abstract (long version below): Narratologists and data scientists alike have long desired to identify a small number of “universal” story archetypes. One such approach, popularized by Kurt Vonnegut, focuses on how emotions develop over story time. This approach has been implemented computationally using automatic sentiment analysis, which attracted criticism due to the limitations of such tools to deal with the complexities of narratives. We contribute to this dialogue with an empirical study of the task of automatically identifying the emotional story arc of movies using subtitles. We validate the emotion arcs against manually annotated labels. The results highlight both challenges and strengths.

")
 Long abstract
Long abstract
Introduction
Several narratologists have argued that all stories originate from a limited set of story structures. Vonnegut (2005) claims that all stories can be plotted through six basic story shapes that abstractly plot good vs ill fortune as a function of time throughout the story (henceforth: emotion arcs). Research by Jockers (2015) and Reagan et al. (2016) purports to conrm this hypothesis using automatic sentiment analysis and machine learning to identify fundamental shapes of story arcs. Such techniques have also been applied to movies (Indico Data, 2015; Del Vecchio et al 2019). These conclusions attracted criticism. First, sentiment analysis is a crude tool for approximating emotions in narrative, a task for which most tools were not designed and can fail spectacularly at: “At least for literature, sentiment analysis is fractally bad: the closer you look at what it’s actually doing, the more problems you nd” (Bowers & Dombrowski, 2021). Second, Enderle (2016) argues that the methods that reduce story shapes to six fundamental types are producing algorithmic artifacts since random noise will also result in the same “fundamental” shapes. Nevertheless, this line of research continues (e.g., Pianzola et al., 2020, Chun 2021, Bizzoni et al., 2022), so a critical empirical appraisal is in order.
Method
In this paper, we assess how well sentiment analysis can predict the emotional arc of movies as annotated through manual annotation, and analyze where the method
succeeds and falters. We adopt Vonnegut’s (2005) notion of a good vs ill fortune axis. Two annotators watched the movies Up (2009) and Guardians of the Galaxy (2014), and manually annotated each minute on a 5-point scale (very negative, somewhat negative, neutral/mixed, somewhat positive and very positive).
Predictions are based on automatic sentiment analysis of the subtitles of the movies. We consider the following sentiment analysis methods: lexicon-based (Hu & Liu, 2004), VADER (Hutto & Gilbert, 2014), and a state-of-the-art neural model (Hugging Face, 2022) trained on a movie review dataset (Socher et al., 2013). The subtitles of each minute are aggregated and fed to the sentiment analysis method, resulting in a score [-1, 1]. The scores are scaled to unit variance (however, we do not apply z-scoring, since the dierence between a positive and negative score should be preserved). The annotations and subtitles are temporally aligned with absolute timestamps; in order to preserve this alignment, we do not apply any transformation that would disrupt this alignment, such as Dynamic Time Warping or other algorithmic methods that reduce the story arc to a supposedly universal, basic plot shape.
The annotations and sentiment analysis predictions are then plotted. The scores are processed by Lowess which smooths the signal using a moving average (similar to Indico Data, 2015); however, the average is weighted such that more distant points have less inuence on the outcome. The “frac” parameter of Lowess determines the amount of smoothing to apply. In this work we use frac=0.1, which means that the moving average is calculated using the surrounding 10% of datapoints; higher values lead to a smoother curve with less detail. In our experiments, frac=0.1 appears to be a good trade-o; a more systematic evaluation is left for future work.
How can the delity of an emotional story arc be determined? It is tempting to come up with simplistic quantitative metrics: accuracy, (rank) correlation, area between the curves, etc. However, Vonnegut (2015) argued that the precise amplitude and temporal aspects of the shapes are details that should be abstracted away in basic story shapes. However, it is dicult to formally dene how much detail a story shape should contain, and the annotation is a subjective task. Therefore, reporting a quantitative evaluation would give a misleading sense of objectivity, and we opt for a qualitative analysis instead. We leave formalizing the evaluation to future work, as it is an important goal, but should not be done in an ad hoc manner.
Brief summary of results
The results highlight the following. Closed Caption (CC; Wikipedia 2023) subtitles provide more accurate emotion arcs than regular subtitles (Figure 1). The neural method results in the best overall emotion arcs (Figure 2). Sentiment analysis struggles with humor and sarcasm, and emotions conveyed visually or non-verbal audio. However, many peaks and valleys in the manually annotated emotion arcs are predicted accurately by automatic sentiment analysis (Figure 2-3). Future work should incorporate sentiment analysis of visual and audio signals.
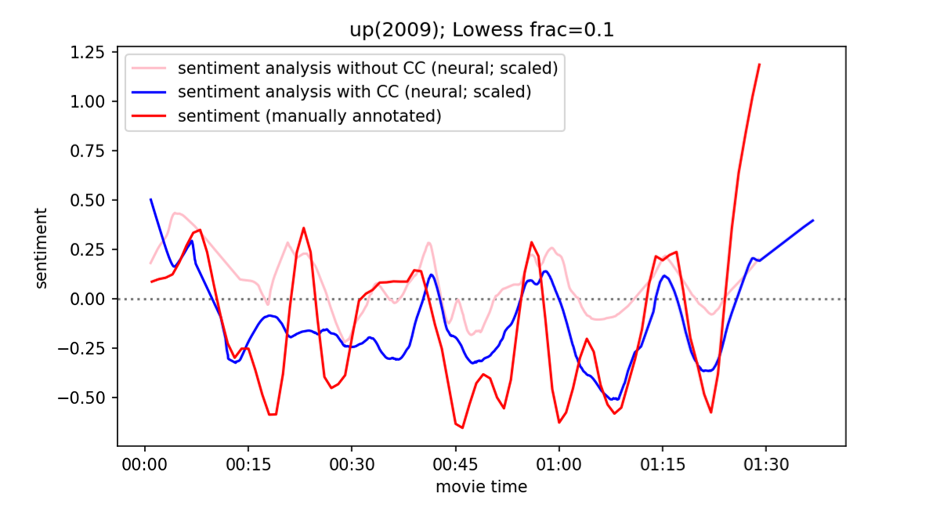
Figure 1: Manual annotations compared with predicted arcs based on subtitles with and without closed captions.
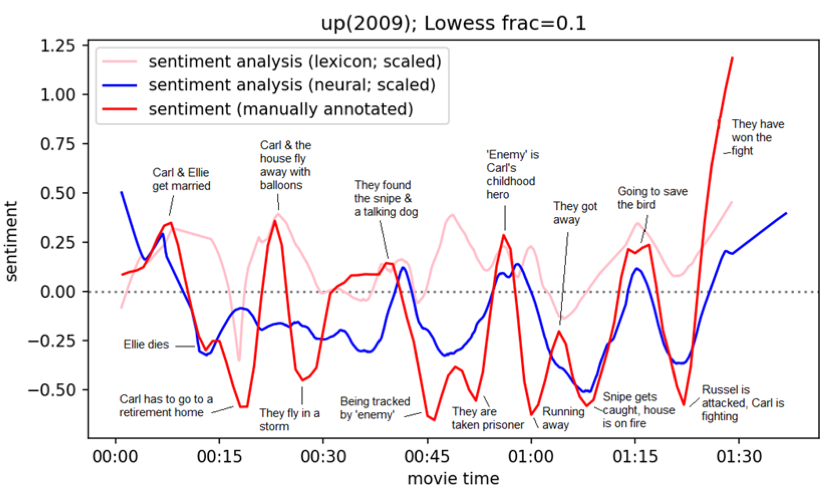
Figure 2: Manual annotations compared with automatic sentiment analysis methods with highlights of important story events.
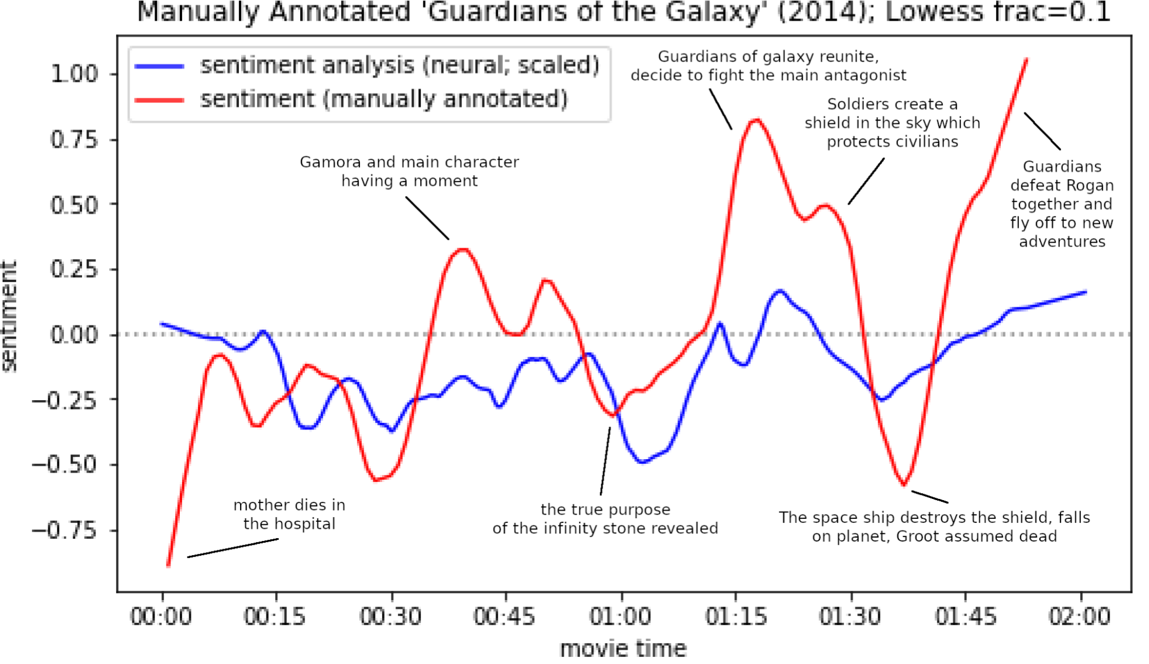
Figure 3: Manual annotations compared with automatic sentiment analysis methods with highlights of important story events.
References
Bizzoni, Yuri, Telma Peura, Mads Thomsen, Kristoer Nielbo (2022). Fractal Sentiments and Fairy Tales - Fractal scaling of narrative arcs as predictor of the perceived quality of Andersen’s fairy tales. Journal of Data Mining & Digital Humanities. #9640 - Fractal Sentiments and Fairy Tales - Fractal scaling of narrative arcs as predictor of the perceived quality of Andersen's fairy tales
Bowers, Katherine and Quinn Dombrowski (2021). Katia and the Sentiment Snobs. The Data-Sitters Club. October 25, 2021. DSC #11: Katia and the Sentiment Snobs — The Data-Sitters Club
Chun, Jun (2021). SentimentArcs: A Novel Method for Self-Supervised Sentiment Analysis of Time Series Shows SOTA Transformers Can Struggle Finding Narrative Arcs. arXiv eprint 2110.09454. [2110.09454] SentimentArcs: A Novel Method for Self-Supervised Sentiment Analysis of Time Series Shows SOTA Transformers Can Struggle Finding Narrative Arcs
Del Vecchio, Marco, Kharlamov, A., Parry, G., & Pogrebna, G. (2021). Improving productivity in Hollywood with data science: Using emotional arcs of movies to drive product and service innovation in entertainment industries. Journal of the Operational Research Society, 72(5), 1110-1137. https://doi.org/10.1080/01605682.2019.1705194
Enderle, Scott (2015). A plot of Brownian noise. Noise
Hu, Minqing and Bing Liu. Mining and Summarizing Customer Reviews. Proceedings of the ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining (KDD-2004), Aug 22-25, 2004, Seattle, Washington, USA. https://doi.org/10.1145/1014052.1014073
Hugging Face Canonical Model Maintainers (2022). distilbert-base-uncased-netuned-sst-2-english (Revision bfdd146). https://huggingface.co/distilbert-base-uncased-netuned-sst-2-english
Hutto, C.J. & Gilbert, E.E. (2014). VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Eighth International Conference on Weblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014. https://www.aaai.org/ocs/index.php/ICWSM/ICWSM14/paper/viewPaper/ 8109
Jockers, Matthew L. (2015). Revealing Sentiment and Plot Arcs with the Syuzhet Package. http://www.matthewjockers.net/2015/02/02/syuzhet/
Swaord, Annie (2015). Continuing the Syuzhet discussion. WordPress.com
Pianzola, Federico, Simone Rebora, Gerhard Lauer (2020). Wattpad as a resource for literary studies. Quantitative and qualitative examples of the importance of digital social reading and readers’ comments in the margins. PLoS ONE 15(1): e0226708. Wattpad as a resource for literary studies. Quantitative and qualitative examples of the importance of digital social reading and readers’ comments in the margins
Reagan, Andrew J., Mitchell, L., Kiley, D., Danforth, C. M., & Dodds, P. S. (2016). The emotional arcs of stories are dominated by six basic shapes. EPJ Data Science, 5(1), 1-12. The emotional arcs of stories are dominated by six basic shapes | EPJ Data Science | Full Text
Socher, Richard, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts (2013). Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the EMNLP, pages 1631–1642. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank - ACL Anthology
Vonnegut, Kurt (2005). At the blackboard: Kurt Vonnegut diagrams the shapes of stories. At the Blackboard | Lapham’s Quarterly
Wikipedia contributors (2023). Closed captioning. In Wikipedia, The Free Encyclopedia. Retrieved 14:27, March 18, 2023, from Sport - Wikipedia 250594